要让编码 Agent 在更少的监督下工作,我们需要提高对其结果的信任度。作为软件工程师,我们对 AI 生成的代码有一种天然的不信任——LLM 具有非确定性,它们不了解我们的上下文,也不真正理解代码,它们以 token 的方式思考。本文探讨了一种心智模型,将上下文工程和工具链工程中的新兴概念结合起来,以建立这种信任。
2026 年 4 月 2 日

Birgitta 是 Thoughtworks 的一名杰出工程师和 AI 辅助交付专家。她拥有超过 20 年的软件开发、架构和技术领导经验。
目录
侧边栏
工具链(harness)一词已成为一个简写,指代 AI Agent 中除了模型本身以外的所有部分——Agent = Model + Harness。这是一个非常宽泛的定义,因此值得在常见的 Agent 类别中进行细化。我在这里想在编码 Agent 使用这一有限上下文中定义其含义。在编码 Agent 中,工具链的一部分已经内置(例如通过系统提示词、选择的代码检索机制,甚至是一个复杂的编排系统)。但编码 Agent 也为我们(用户)提供了许多功能,让我们能够构建一个专门针对自身用例和系统的外部工具链。
隐喻的作用有限
有人曾向我指出,在工具链里再套工具链毫无意义:“你有没有试过在狗的内部套上工具链?“所以这个比喻确实有些牵强,但如果它有助于导航这个词的使用,我愿意接受它。
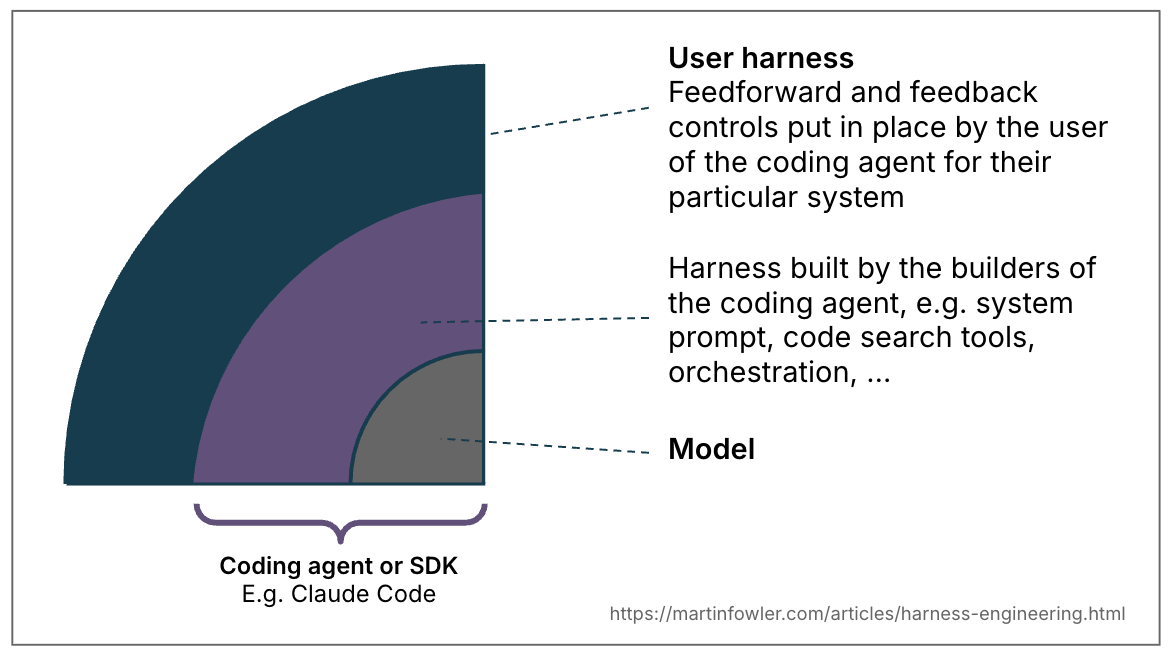
图 1:“工具链”一词在不同上下文中含义不同。
一个设计良好的外部工具链服务于两个目标:它提高了 Agent 第一次就做对的概率,并提供了一个反馈循环,在问题到达人工审查之前尽可能多地进行自我纠正。最终,它应该减少审查工作量并提高系统质量,同时还减少了不必要的 token 消耗。
![Title "Harness engineering for coding agent users". Overview of guides (examples shown are [inferential] principles, CfRs, Rules, Ref Docs, How-tos; [computational] Language Servers, CLIs, scripts, codemods) that feedforward into a coding agent; and feedback sensors (examples shown are [inferential] review agents; [computational] static analysis, logs, browser). The feedback sensors point at the coding agent as well as input into its self-correcting loop. On the left side of it all we see a box with a human who steers both the guides and sensors.](https://martinfowler.com/articles/harness-engineering/harness-overview.png)
前馈与反馈
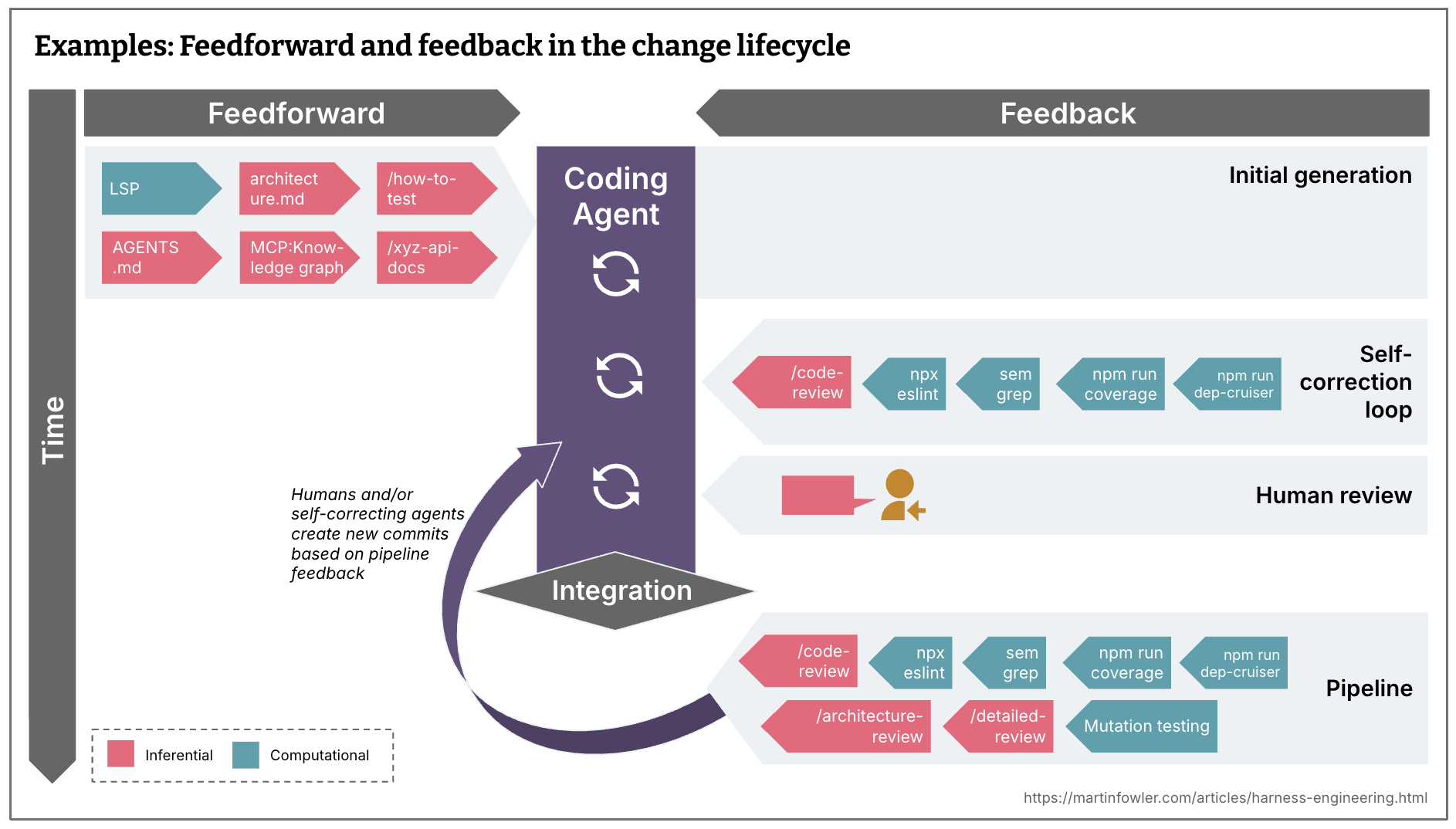
要对编码 Agent 进行”工具链化”,我们需要同时做两件事:预测不想要的输出并尽量防止它们发生,以及设置传感器让 Agent 能够自我纠正:
- 指南(feedforward controls,前馈控制)——在 Agent 行动之前预测其行为并引导其行动。指南提高了 Agent 第一次就产生好结果的概率。
- 传感器(feedback controls,反馈控制)——在 Agent 行动之后观察结果,帮助其自我纠正。当传感器产生针对 LLM 消费优化的信号时特别强大,例如包含自我纠正指令的自定义 linter 消息——一种积极的提示注入。
如果只有其中之一,要么得到一个不断重复相同错误的 Agent(仅有反馈),要么得到一个编码了规则但从不知道这些规则是否有效的 Agent(仅有前馈)。
计算型 vs 推理型
指南和传感器有两种执行类型:
- 计算型(Computational)——确定性的、快速的,由 CPU 运行。测试、linter、类型检查器、结构分析。毫秒到秒级运行,结果可靠。
- 推理型(Inferential)——语义分析、AI 代码审查、“LLM 即裁判”。通常由 GPU 或 NPU 运行。更慢且更昂贵,结果更具非确定性。
计算型指南通过确定性工具提高好结果的概率。计算型传感器足够便宜和快速,可以对每次变更运行,与 Agent 并行执行。当然,推理型控制的成本更高且具有非确定性,但允许我们提供丰富的指导,并添加额外的语义判断。尽管具有非确定性,当与强模型配合使用时——或者更准确地说,与适合当前任务的模型配合使用时——推理型传感器尤其能提高我们的信任度。
示例
| 方向 | 计算型/推理型 | 示例实现 | |
|---|---|---|---|
| 编码规范 | 前馈 | 推理型 | AGENTS.md、Skills |
| 如何引导新项目的说明 | 前馈 | 两者皆有 | 包含说明和引导脚本的 Skill |
| Code mods | 前馈 | 计算型 | 访问 OpenRewrite 配方的工具 |
| 结构测试 | 反馈 | 计算型 | 运行 ArchUnit 测试的前提交钩子(或编码 Agent),检查模块边界的违规情况 |
| 如何审查的说明 | 反馈 | 推理型 | Skills |
工具链工程与上下文工程有什么关系?
上下文工程 为我们提供了让指南和传感器对 Agent 可用的手段。为编码 Agent 工程化一个用户工具链是上下文工程的一种特定形式。
驾驶循环
人类在这项工作中的职责是驾驶 Agent,通过迭代优化工具链。当一个问题多次发生时,前馈和反馈控制应该被改进,使问题在未来发生的概率降低,甚至完全防止。
在驾驶循环中,我们当然也可以使用 AI 来改进工具链。编码 Agent 现在使构建更多自定义控制和更多自定义静态分析变得更便宜。Agent 可以帮助编写结构测试、从观察到的模式生成规则草稿、搭建自定义 linter,或从代码库考古中创建操作指南。
时机:保持质量靠左
采用持续集成的团队一直面临着根据成本、速度和关键性,将测试、检查和人工审查分布到开发时间线上的挑战。当你追求持续交付时,理想情况下你甚至希望每个提交状态都是可部署的。你希望检查尽可能靠近生产路径的左侧,因为问题发现得越早,修复成本就越低。反馈传感器,包括新的推理型传感器,需要根据生命周期分布。
变更生命周期中的前馈和反馈
- 什么足够快,可以在天前甚至提交前运行?(例如 linter、快速测试套件、基本代码审查 Agent)
- 什么更昂贵,因此只能在天后在管道中运行,同时重复快速控制?(例如变异测试、更广泛的代码审查,可以从天整体角度考虑)
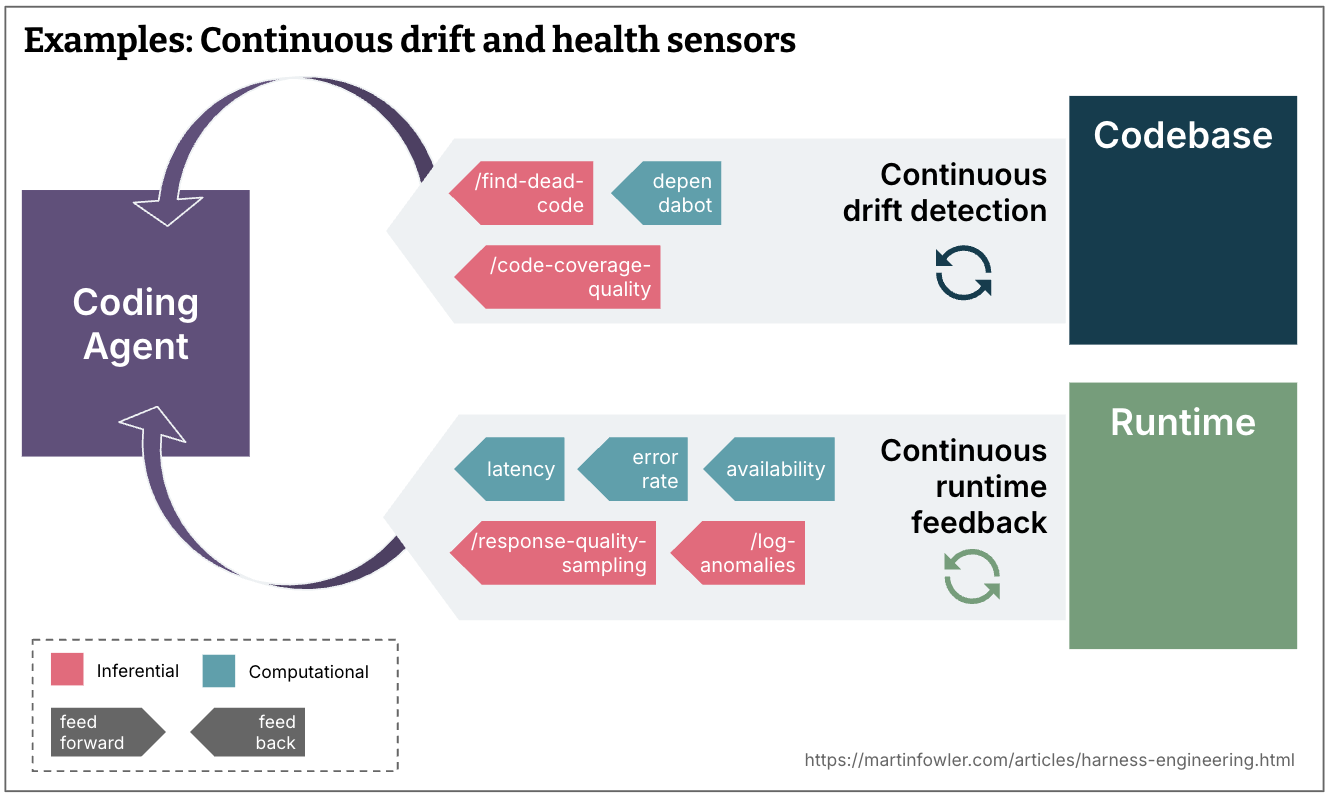
持续漂移和健康传感器
- 什么样的漂移是逐渐累积的,应该通过持续对代码库运行的传感器来监控,在变更生命周期之外?(例如死代码检测、测试覆盖质量分析、依赖扫描器)
- Agent 可以监控什么样的运行时反馈?(例如让它们查找降级的 SLO,并提出改进建议;或 AI 裁判持续采样响应质量并标记日志异常)
规管类别
Agent 工具链充当一个控制论调节器,结合前馈和反馈来调节代码库达到其期望状态。区分期望状态的多个维度是很有用的,按工具链应该规管的类别来划分。区分这些类别是有帮助的,因为它们的可工具链化和复杂性各不相同,而这个词语的其他用法——原本是一个非常通用的术语——让我们有了更精确的语言。
以下是我目前认为有用的三个类别:
可维护性工具链
我在本文中给出的几乎所有例子都与调节内部代码质量和可维护性有关。这是目前最容易的工具链类型,因为我们有大量可用的现有工具。
为了反思这些可维护性工具链的想法在多大程度上提高了我们对 Agent 的信任,我将之前编目的常见编码 Agent 失败模式与之对应。
计算型传感器可靠地捕获结构性问题:重复代码、圈复杂度、缺失的测试覆盖、架构漂移、风格违规。这些是便宜的、经过验证的、确定性的。
LLM 可以部分解决需要语义判断的问题——语义重复的代码、冗余测试、蛮力修复、过度工程的解决方案——但成本高昂且具有概率性。不是每个提交都会处理。
有些更高影响的问题两类传感器都无法可靠地捕获:问题误诊、过度工程和不必要的功能、误解指令。它们有时会捕获这些问题,但不够可靠,无法减少监督。如果人类一开始没有明确指定他们想要什么,那么正确性就不在任何传感器的职责范围内。
架构 Fitness 工具链
这组指南和传感器定义并检查应用程序的架构特征。基本上:Fitness Functions。
示例:
- 前馈我们的性能需求的技能,以及在性能改进或降级时向 Agent 反馈的性能测试。
- 描述更好可观测性的编码约定的技能(如日志标准),以及要求 Agent 反思其可用的日志质量的调试说明。
行为工具链
这是房间里的大象——我们如何引导和感知应用程序的功能行为是否如我们所愿?目前,我看到大多数给予编码 Agent 高自主权的团队这样做:
- 前馈:一项功能规范(详细程度不同,从简短的提示词到多文件描述)
- 反馈:检查 AI 生成的测试套件是否通过,覆盖率是否合理,一些人甚至用变异测试监控其质量。然后结合人工测试。
这种方体对 AI 生成的测试有很大的信任,但这还不够好。我的一些同事在使用approved fixtures模式时看到了很好的结果,但它在某些领域比其他领域更容易应用。他们在适合的地方有选择地使用它,这不是测试质量问题的万能答案。
所以总的来说,我们还有很多要做,以找出能足够提高我们的信心来减少监督和手动测试的功能行为工具链。
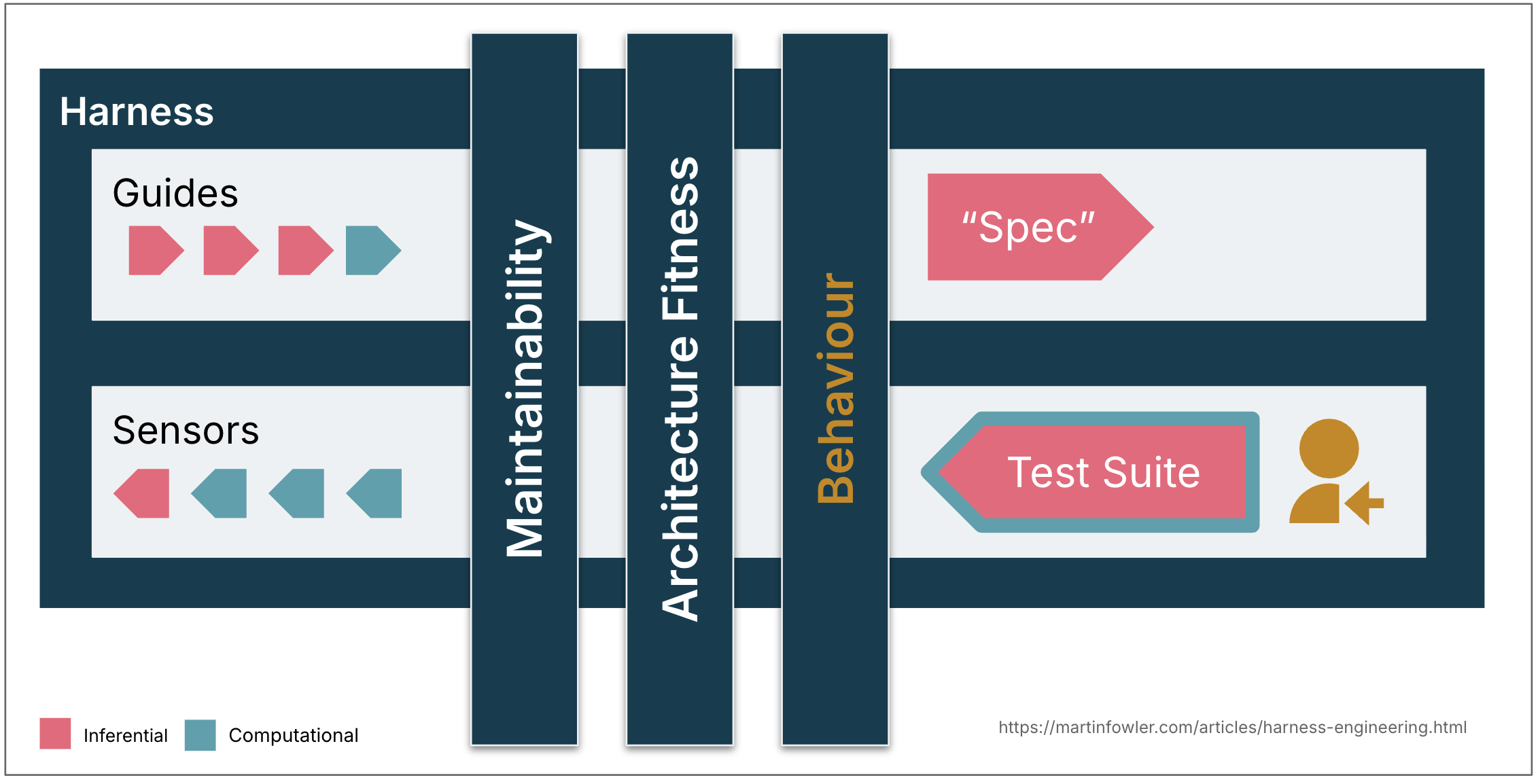
工具链化能力
并非每个代码库都同样容易工具链化。用强类型语言编写的代码库自然有类型检查作为传感器;边界定义清晰的模块有利于架构约束规则;Spring 等框架抽象掉了 Agent 甚至不需要担心的细节,因此隐含地提高了 Agent 成功的机会。没有这些属性,这些控制就无法构建。
环境可供性
我的同事 Ned Letcher 使用”环境可供性”(ambient affordances)一词来描述使 Agent 环境更具工具链性的属性:“环境本身的结构属性,使其对在其中运行的 Agent 具有可读性、可导航性和可处理性。”
这对新项目与遗留代码有不同的表现。新项目团队可以从第一天起就将工具链化能力融入其中——技术决策和架构选择决定了代码库的可管理程度。遗留代码团队,特别是累积了大量技术债务的应用程序,面临更难的问题:工具链最需要的地方恰恰是最难构建的。
工具链模板
大多数企业有几类常见的服务拓扑,覆盖了他们 80% 的需求——通过 API 暴露数据的业务服务、事件处理服务、数据仪表板。在许多成熟的工程组织中,这些拓扑已经以服务模板的形式编纂。这些未来可能会演变为工具链模板:一组指南和传感器的捆绑,将编码 Agent 约束到拓扑的结构、约定和技术栈上。团队可能开始根据已有的工具链来选择技术栈和结构。
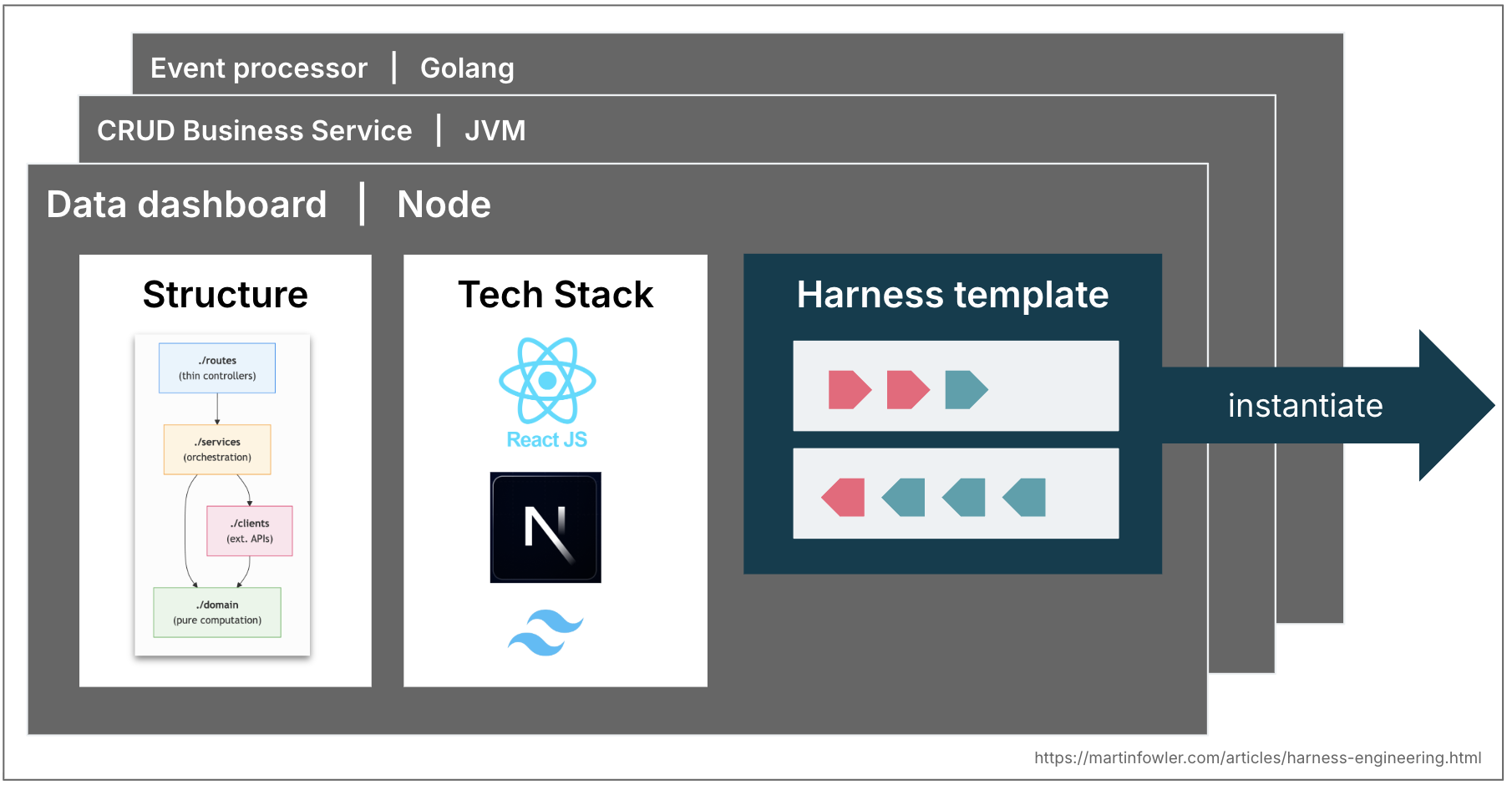
Ashby 定律
Ashby 的必要多样性定律是这些预定义拓扑的另一个有趣论证。该定律指出,调节器必须具有至少与其所调节的系统一样多的多样性,而且它只能调节它有模型的东西。基于 LLM 的编码 Agent 可以产生几乎任何东西,但承诺一个拓扑会缩小这个空间,使全面的工具链更容易实现。定义拓扑是一种多样性减少的举措。
当然,我们当然会面临与服务模板类似的挑战。一旦团队实例化它们,它们就会开始与上游改进不同步。工具链模板将面临相同的版本化和贡献问题,当非确定性指南和传感器更难测试时,情况可能更糟。
人的角色
作为人类开发者,我们将技能和经验作为隐式工具链带到每个代码库。我们吸收了约定和良好实践,感受过复杂性的认知痛苦,我们知道我们的名字在提交记录上。我们还携带组织对齐——对团队试图实现什么的认识,哪种技术债务因为业务原因被容忍,以及在这个特定上下文中”好”是什么样子。我们以小步骤和人类的速度进行,这为经验的触发和应用创造了思考空间。
编码 Agent 没有这些:没有社会责任、没有对 300 行函数的审美厌恶、没有”这里不这样做”的直觉,也没有组织记忆。它不知道哪个约定是承重的,哪个只是习惯,或者技术上正确的解决方案是否适合团队正在尝试做的事情。
工具链是尝试外部化和明确化人类开发者经验带到桌面的东西,但这只能走到这一步。构建一套连贯的指南、传感器和自我纠正循环是昂贵的,所以我们必须以明确的目标为优先:一套好的工具链不一定要aim to fully eliminate human input,而是将人工投入引导到最需要的地方。
起点——以及开放问题
我在这里阐述的心智模型描述了已经在实践中发生的技术,并有助于框定关于我们仍需要弄清楚什么的讨论。它的目标是将对话提升到功能级别以上——从 Skills 和 MCP 服务器到我们如何战略性地设计一个控制系统,让我们对 Agent 产生的东西有真正的信心。
以下是当前讨论中的一些工具链相关示例:
- 一个 OpenAI 团队记录了他们的工具链是什么样的:由自定义 linter 和结构测试强制的分层架构,以及 recurring”垃圾收集”,扫描漂移并让 Agent 建议修复。他们的结论:“我们最困难的挑战现在集中在设计环境、反馈循环和控制系统上。”
- Stripe 关于他们的 minions 的文章描述了基于启发式运行相关 linter 的天前推送钩子等内容,它们强调”将反馈向左移”对他们来说有多重要,他们的”蓝图”展示了他们如何将反馈传感器集成到 Agent 工作流中。
- 变异和结构测试是过去未被充分利用的计算型反馈传感器的例子,但现在正在复苏。
- 开发者之间关于将 LSP 和代码智能集成到编码 Agent 的讨论越来越多,这是计算型前馈指南的例子。
- 我听到 Thoughtworks 团队使用计算型和推理型传感器解决架构漂移的故事,例如用混合 Agent 和自定义 linter 提高 API 质量,或用”清洁工军队”提高代码质量。
还有很多需要弄清楚的问题,不仅仅是上述的行为工具链。当工具链增长、指南和传感器需要同步且不相互矛盾时,如何保持工具链的连贯性?当说明和反馈信号指向不同方向时,我们能相信 Agent 进行合理的权衡吗?如果传感器从不触发,那是高质量的标志还是检测机制不足?我们需要一种评估工具链覆盖率和质量的方法,类似于代码覆盖率和变异测试对测试的作用。前馈和反馈控制目前分散在交付步骤中,有真正的潜力可以帮助配置、同步和推理它们作为一个系统。构建这个外部工具链正在成为一项持续的工程实践,而不是一次性配置。
致谢
非常感谢 Doppler 团队在我们上一次技术雷达会议上进行的精彩讨论,特别是 Kief Morris 提出了控制论。感谢 Ned Letcher、Chris Ford 和 Ben O’Mahoney 关于什么是工具链的对话,以及 Matteo Vaccari 关于行为工具链的见解。还要感谢抽出时间阅读草稿并提供大量宝贵反馈的每一个人:Christoph Burgmer、Jörn Dinkla、Michael Feathers、Karrtik Iyer、Swapnil Phulse、Paul Sobocinski、Zhenjia Zhou
GenAI(Claude 和 Claude Code)用于研究、从中引入相关想法现有笔记,以及润色语言。
早期备忘录
我在 2 月初写了一份备忘录,包含了我对工具链工程作为术语首次出现时的初步想法。那篇文章吸引了很多流量。本文取代了那篇备忘录,所以我们将原始备忘录 URL 重定向到此页面,因为我们相信本文是读者的更好资源。
重要修订
2026 年 4 月 2 日: 发布完整文章,包括介绍指南、传感器、计算型和推理型元素,以及工具链模板